秋招以来,为了找工作又学习了很多python相关的知识,给大家分享一下,里面好多内容都是我东拼西凑出来的(如果是借鉴了其他博客的,希望大家可以指出,我会标注上),感觉都是比较常见的或者被问到的。
希望这篇分享会对大家找工作有所帮助~
1. GIL及多线程相关
背景概念:
- 支持多线程:不同线程对共享资源访问的互斥
- 多线程带来的问题:多线程是可以共享变量的,同时执行可能会导致数据被污染造成数据混乱,这是线程的不安全性,引入互斥锁。
- 互斥锁:确保某段关键的代码数据只能有一个线程从头到尾完整执行,保证了这段代码数据的安全性,但是这也会导致死锁。
- 死锁:多个子线程在等待对方解除占用状态,但是都不先解锁,互相等待,导致死锁。
python中的多线程
GIL锁(Global Interpreter Lock):为了利用多核,python开始支持多线程,解决多线程之间数据完整性和状态同步的最简单方法就是加锁,GIL是Python的全局解释器锁,GIL确保每次只能执行一个“线程”。一个线程获取GIL执行相关操作,然后将GIL传递到下一个线程。
虽然看起来程序被多线程并行执行,但它们实际上只是轮流使用相同的CPU核心。所有这些GIL传递都增加了执行的开销。这意味着多线程并不能让程序运行的更快。
同一进程中如有多个线程运行,一个线程在运行时会霸占python解释器,加了一把锁即GIL,使该进程内的其他线程无法运行,等该线程运行完后其他线程才运行,如果线程运行过程中遇到耗时的操作(阻塞),则解释器锁解开,使其他线程运行,所以在多线程中,线程的运行仍然是有先后顺序的,并不是同时进行的。在同一时刻,只能有一个线程在一个cpu上执行字节码,没法像C和JAVA一样将多个线程映射到多个CPU上执行,但是GIL会根据执行的字节码行数和时间片以及遇到的IO操作的时候主动释放锁,让其他字节码进行。多线程爬取单线程性能有所提升,因为遇到IO操作阻塞会释放GIL锁,会在合适的时间转换到其他线程执行。
基于GIL的存在,在遇到大量IO操作代码时,使用多线程效率更高。
计算密集型(大量计算不停止一直算),用多进程
IO密集型(读写),用线程(利用等待的时间加速),协程也是适合io密集型
多线程怎么使用多核: 1、重写python编译器(官方cpython)如使用:PyPy解释器 2、调用C语言的链接库
明确GIL不是Python的特性,是实现Python解析器(Cpython)时引入的一个概念,python的解析器还有Pypy、psyco等,大部分环境下默认是Python的执行环境。
2. python多线程、多进程实践
1)背景知识概念
多任务:同一时间执行多个任务,可以充分利用计算资源,提升执行效率
多任务执行方式:
- 并发:在一段时间内交替(时间非常短)去执行多个任务,单核CPU处理多任务,操作系统轮流让各个任务交替的执行。任务数量大于CPU核心数
- 并行:在一段时间内真正的同时一起执行多个任务,多核CPU,操作系统给CPU的每一个内核安排一个执行的任务,多个内核一起同时执行任务,任务数量小于或者等于CPU核心数
2)在python中想要实现多任务,需要使用多进程来完成
- 进程是操作系统资源分配(内存、磁盘、网络)的最小单位,是一个运行的程序,如正在运行的QQ、微信等。一个运行的程序至少有一个进程
没有多进程时候是只有一个主进程,多进程的时候是额外创建多个子进程
python多进程实践
1 | # 导入包 |
进程执行带有参数的任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import multiprocessing
import time
def sing(num):
for i in range(num):
print('i am singing')
time.sleep(0.5)
def dance(num):
for i in range(num):
print('i am dancing')
time.sleep(0.5)
if __name__ == '__main__':
# args指定使用元组的方式给指定任务传参,按顺序传给任务传参,一定要和参数的顺序一致
# kwargs指定字典的方式给指定任务传参,key就是参数的名字,必须严格一致。按照key的名字传参。
p1 = multiprocessing.Process(target = sing,args=(3,));
p2 = multiprocessing.Process(target = dance,kwargs={'num':2});
p1.start()
p2.start()对进程的管理-获取进程编号
import os获取当前进程编号pidos.getpid(),获取当前进程父进程的编号pidos.getppid()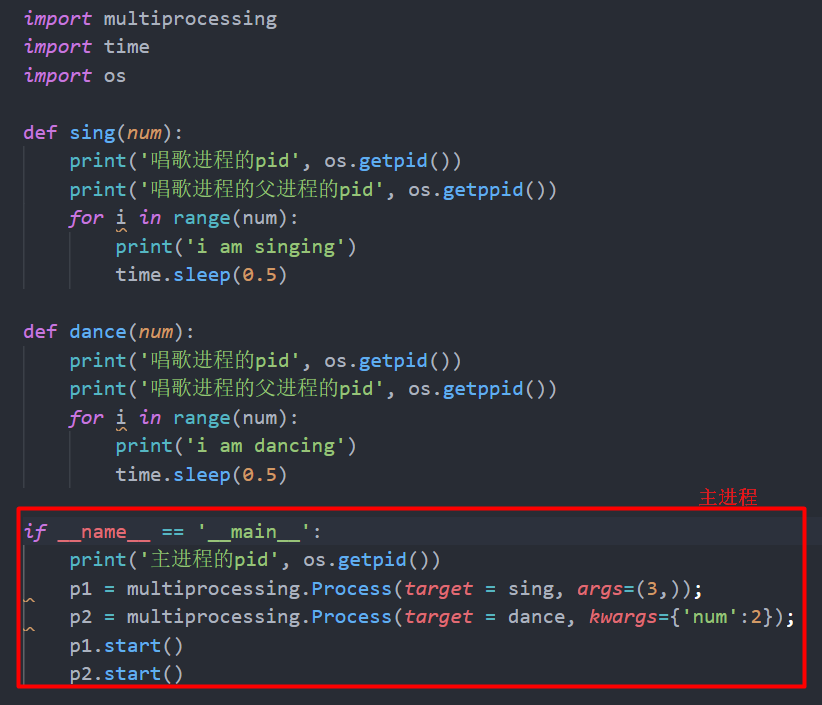
守护主进程
主进程会等待所有的子进程执行结束再结束,但是我们希望主进程结束,子进程也直接销毁,不再执行子进程中的代码,这就需要设置守护主进程:
子进程.daemon = True1
2
3
4
5
6
7
8
9
10
11
12
13
14import multiprocessing
import time
def work(num):
for i in range(num):
print('i am working')
time.sleep(0.2)
if __name__ == '__main__':
p = multiprocessing.Process(target = work, args=(20,));
p.daemon = True # 这个一定要放在start之前
p.start()
time.sleep(1)
print('work done!')
3)Python多线程:线程是程序执行的最小单位,共享同一个进程的资源,可以实现多任务。
Python多线程实践:
1
2
3
4
5
6
7
8
9
10# 导入包
import threading
# 创建进程对象
线程对象 = threading.Thread(target = 任务名字(函数名、方法名))
#Process还有两个属性: name,给线程指定一个名字,通常系统会自动给出名字,group,线程组,目前只能使用None。
# 启动进程执行任务
线程对象.start()整个都和多进程一样,可以试着去做一下线程执行带有参数的任务,和进程保持一致。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import threading
import time
def sing(num):
for i in range(num):
print('i am singing')
time.sleep(0.2)
if __name__ == '__main__':
# 下面是两种设置守护线程的方式
# t = threading.Thread(target = sing,args=(10,), daemon=True);
t = threading.Thread(target = sing,args=(10,));
t.setDaemon(True)
t.start()
time.sleep(1)
print('well done!')多线程之间的执行是无序的,是由CPU调度决定的、操作系统决定的。
1 | import threading |
4)关系对比
- 线程依附在进程里面,没有进程就没有线程
一个进程默认提供一条线程,进程可以创建多个线程
区别对比
- 创建进程的资源开销比创建线程的资源开销大
- 进程是操作系统资源分配的基本单位,线程是CPU调度的单位
- 线程不能独立运行,依附进程
优缺点对比
- 进程:开销大,可以利用多核
- 线程,开销小,不能用多核
首先,如果不做任何限制,主线程执行完,子线程再继续执行;如果加上守护进程,主线程执行完,子线程无法执行;利用Join(),主线程等子线程执行完毕再执行(join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程在终止)
join有一个timeout参数:
- 当设置守护线程时,含义是主线程对于子线程等待timeout的时间将会杀死该子线程,最后退出程序。所以说,如果有10个子线程,全部的等待时间就是每个timeout的累加和。简单的来说,就是给每个子线程一个timeout的时间,让他去执行,时间一到,不管任务有没有完成,直接杀死。
- 没有设置守护线程时,主线程将会等待timeout的累加和这样的一段时间,时间一到,主线程结束,但是并没有杀死子线程,子线程依然可以继续执行,直到子线程全部结束,程序退出。
5)pyton多进程、线程、协程,多进程怎么通信
协程
线程是系统级别的,它们是由操作系统调度;协程是程序级别的,由程序员根据需要自己调度。我们把一个线程中的一个个函数叫做子程序,那么子程序在执行过程中可以中断去执行别的子程序;别的子程序也可以中断回来继续执行之前的子程序,这就是协程。也就是说同一线程下的一段代码<1>执行着执行着就可以中断,然后跳去执行另一段代码,当再次回来执行代码块<1>的时候,接着从之前中断的地方开始执行。
- yield实现协程
- greenlet,手动切换
- gevent实现协程:第三方库
通信
- pip:适用于两个进程一个读一个写的单双工情况,信息是一个方向的流动 ,读写效率高于queue
- queue:多个进程进行读或者多个进程进行写
在一个进程中,不同子线程负责不同的任务,t1子线程负责获取到数据,t2子线程负责把数据保存的本地,那么他们之间的通信使用Queue来完成。因为再一个进程中,数据变量是共享的,即多个子线程可以对同一个全局变量进行操作修改,Queue是加了锁的安全消息队列。
6)线程同步
如果没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预期,这种现象称为“线程不安全”
同步的意思是:进程或线程A和B一块配合,A执行到1一定程度的时候要依靠B的某个结果,于是停下来,示意B运行;B运行后,再将结果传给A;A再继续操作。
线程锁实现同步控制
线程锁使用threading.Lock()实例化,使用acquire()上锁,使用release()释放锁,acquire()和release()必须同时成对存在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48def run1():
while 1:
if l1.acquire():
# 如果第一把锁上锁了
print('我是老大,我先运行')
l2.release()
# 释放第二把锁
def run2():
while 1:
if l2.acquire():
# 如果第二把锁上锁了
print('我是老二,我第二运行')
l3.release()
# 释放第三把锁
def run3():
while 1:
if l3.acquire():
# 如果第三把锁上锁了
print('我是老三,我最后运行')
l1.release()
# 释放第一把锁
t1 = threading.Thread(target=run1)
t2 = threading.Thread(target=run2)
t3 = threading.Thread(target=run3)
l1 = threading.Lock()
l2 = threading.Lock()
l3 = threading.Lock()
# 实例化三把锁
l2.acquire()
l3.acquire()
t1.start()
t2.start()
t3.start()
output:
我是老大,我先运行
我是老二,我第二运行
我是老三,我最后运行
我是老大,我先运行
我是老二,我第二运行
我是老三,我最后运行
我是老大,我先运行
我是老二,我第二运行
我是老三,我最后运行
.....条件变量实现同步精准控制
信号量实现定量的线程同步
semaphore适用于控制进入数量的锁,好比文件的读写操作,写入的时候一般只用一个线程写,如果多个线程同时执行写入操作的时候,会造成写入数据混乱,读取的时候可以用多个线程读取,即写与写是互斥的,读与写不是互斥的,读与读不是互斥的。
BoundedSemaphore,这种锁允许一定数量的线程同时更改数据,不是互斥锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14import time
import threading
def run(n, se):
se.acquire()
print("run the thread: %s" % n)
time.sleep(1)
se.release()
# 设置允许5个线程同时运行
semaphore = threading.BoundedSemaphore(5)
for i in range(20):
t = threading.Thread(target=run, args=(i,semaphore))
t.start()运行后,即5个一批的线程被放行,用来控制进入某段代码的线程数量
3. map函数和reduce函数
map函数返回的是一个生成器。map函数的第一个参数是function,第二个参数一般是list,第三个参数可以是List,也可以不写。通过函数function依次作用在list上的每个元素,得到一个新的List返回。

reduce函数的参数必须接受两个参数,reduce()函数将传入的函数作用在序列的第一个元素得到结果后,把这个结果继续与下一个元素作用(累积计算),最终结果是所有的元素相互作用的结果。

map函数省去了for循环的过程,lambda省去了定义函数
4. python中断言
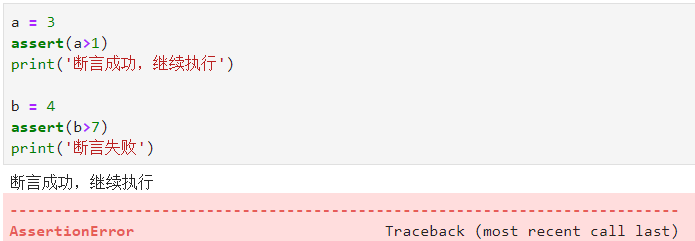
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
用来检查一个条件,如果为真,就不做任何事情,如果为假,提示assertionError异常信息
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。
5. Python2和3的区别
- python3使用Print必须加小括号打印内容,python2既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容
- python2中的range是生成一个列表 range(3)-->[0,1,2], xrange是一个生成器,python3中的range是一个可迭代对象,既不是生成器也不是迭代器
- python2中使用ASCII编码,python使用UTF-8编码
- python2中unicode表示字符串序列,str表示字节序列,python2中str表示字符串序列,byte表示字节序列
- python2中为正常显示中文,引入coding声明,python3不需要
- python2中是raw_input(),python3中是Input()函数
- python2中除法是默认向下取整,为整型,python3是正常除法,为浮点型
- python2中的字典使用开放地址法解决冲突,python3用的是链地址法
6. 异常捕获和处理
常见异常
AttributeError 属性异常 比如foo.x,但是foo没有x属性
IOError 输入输出异常,基本上是无法打开文件
ImportError 无法引入模块或包;基本上是路径问题或名称错误 IndentationError 语法错误(的子类) ;代码没有正确对齐 IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError 试图访问字典里不存在的键 KeyboardInterrupt Ctrl+C被按下 NameError 使用一个还未被赋予对象的变量 SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError 传入对象类型与要求的不符合 UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它 ValueError 传入一个调用者不期望的值,即使值的类型是正确的
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
1
2
3
4
5
6
7
8try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生使用except而不带任何异常类型
1
2
3
4
5
6try:
正常的操作
except:
发生异常,执行这块代码
else:
如果没有异常执行这块代码以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
触发异常
raise语句自己触发异常,触发以后不再执行后面的语句1
2
3
4def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行
7. 提高python运行效率的方法
使用生成器,可以节约大量内存
循环代码优化,避免过多重复代码的执行
核心模块用Cpython PyPy等
python没有专门机构负责实现,多个社区实现的。Cpython是C语言实现的Python,用java开发的JPython,Cpython使用解释执行的方式,性能差,但是PyPy是JIT(即时编译),性能上得到了提升。但是PyPy无法支持官方的C/Python API,无法使用Numpy或Scipy等第三方库。
多进程、多线程、协程
多个if elif条件判断,可以把最优可能先发生的条件放到前面写,这样减少判断次数
8. python中的命名方式、魔法方法
Python中一切皆对象,函数也不例外,函数作为对象可以赋值给一个变量、可以作为元素添加到集合对象中、可作为参数值传递给其它函数,还可以当做函数的返回值,这些特性就是第一类对象所特有的。

public类型
- xx : 公用方法,公有变量没有以下划线开头的变量或者方法是public类型。
- public类型可以被子类、类内以及类外被访问。
- 在python中数据和方法默认都是pubic类型的,此时方法和变量名都没有下划线。
protected类型
- _xx : 半保护方法, 以单下划线开头表示的是protected类型的变量或者方法。
- 只有类对象和子类对象自己能够访问到这些变量,在模块或类外不可以使用,不能用from module import *导入,为了避免和子类的方法名称冲突,对于该标识符描述的方法,父类的方法不能轻易地被子类方法覆盖,他们的名字实际上是_classname_methodname
private类型
1、 __xx :全私有,全保护,双下划线表示的是私有类型的变量或者方法。 2、private类型只能允许类内进行访问。 只能类对象自己访问,不能用from module import *导入。
除此以外
- __object__ 内建方法,用户不要定义,python中的魔方方法
- xx_:用于避免和Python关键词冲突
魔方方法
在Python中以两个下划线开头的方法,__init__、__str__、__doc__、__new__等,被称为"魔术方法"(Magic methods)。魔术方法在类或对象的某些事件出发后会自动执行,如果希望根据自己的程序定制自己特殊功能的类,那么就需要对这些方法进行重写。注意:Python 将所有以 __(两个下划线)开头的类方法保留为魔术方法。所以在定义类方法时,除了上述魔术方法,建议不要以 __ 为前缀。
- __new__:
- 在实例创建前被调用,其任务为创建实例然后返回该实例对象,是个静态方法创建对象时候执行的方法。
- 至少有一个参数cls,代表当前类,此参数在实例化时由python自动识别
- 必须要有返回值,返回实例化出的实例,返回值(实例)将传递给init方法的第一个参数(self)
- __init__:
- 当实例对象创建完后被调用,然后设置对象属性的一些初始值,通常用在初始化一个类实例的时候,是一个实例方法。
- init有一个参数self,这就是new返回的实例,init可以在new基础上完成一些其他初始化的动作,
- Init不需要返回值
__str__:使用Print输出对象的时候,只要自己定义了str方法,就会打印从这个方法中return的数据
__del__:删除对象执行的方法
9. python引用计数机制 垃圾回收机制 gc模块
https://foofish.net/python-gc.html 这个博客讲的不错
垃圾回收
垃圾回收机制定义:
垃圾回收时,Python不能进行其它的任务。频繁的垃圾回收将大大降低Python的工作效率。如果内存中的对象不多,就没有必要总启动垃圾回收。所以,Python只会在特定条件下,自动启动垃圾回收。当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数,当两者的差值高于某个阈值时,垃圾回收才会启动。我们可以通过gc模块的get_threshold()方法,查看该阈值:
1
2import gc
print(gc.get_threshold())返回(700, 10, 10),后面的两个10是与分代回收相关的阈值,后面可以看到。700即是垃圾回收启动的阈值。可以通过gc中的set_threshold()方法重新设置。我们也可以手动启动垃圾回收,即使用gc.collect()。
垃圾回收作用:
- 找到内存中无用的垃圾资源
- 清除这些垃圾并把内存让出来给其他对象使用
- 解决内存泄露问题:内存空间在使用完毕后未释放
引用计数(Reference Counting):
引用计数定义及使用过程
每个对象维护一个
ob_ref字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。引用次数增加:创建对象,对象被引用(赋值操作),对象作为参数传递到函数,对象作为元素存储到容器中。
它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。
循环引用:
会使得引用对象的引用计数不能为0,然而这些对象实际上并没有被任何外部对象所引用,他们只是相互引用,A和B相互引用而再没有外部引用A与B中的任何一个,它们的引用计数虽然都为1,但显然应该被回收,例子:
1
2
3
4
5
6
7
8
9
10import sys
a = {} # A引用计数为1
b = {} # B引用计数为2
a['b'] = b # B引用计数加1
b['a'] = a # A引用计数加1
print(sys.getrefcount(a)) #获取引用计数 输出为3因为a作为参数传给了getrefecount
print(sys.getrefcount(b)) #输出为3
del a # a引用计数减一
del b # b引用计数减一上述例子中,执行完del语句后,没有任何引用指向这两个对象,但是两个对象各包含一个对方对象的引用,但是都不能使用了,就可以理解为垃圾对象,但是引用计数都不为0,就不会被回收,留在内存中,就造成了内存泄露。由此引入标记-清楚和分代(隔代)回收两种gc机制
垃圾回收机制具体实现
标记清楚(Mark-Sweep)
- 标记清除(Mark—Sweep)算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:
- 标记阶段:GC把所有的『活动对象』打上标记
- 回收阶段:把那些没有标记的对象『非活动对象』进行回收。
那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
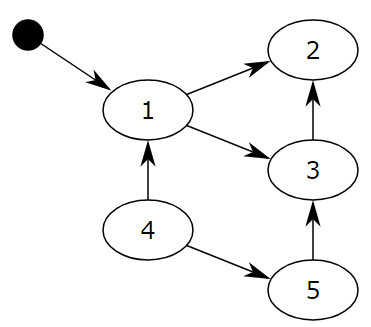
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
举例:
把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法主要用处:
作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。
缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
- 标记清除(Mark—Sweep)算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:
分代回收
这一策略的基本假设是,存活时间越久的对象,越不可能在后面的程序中变成垃圾。我们的程序往往会产生大量的对象,许多对象很快产生和消失,但也有一些对象长期被使用。出于信任和效率,对于这样一些“长寿”对象,我们相信它们的用处,所以减少在垃圾回收中扫描它们的频率。
Python将所有的对象分为0,1,2三代。所有的新建对象都是0代对象。当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。垃圾回收启动时,一定会扫描所有的0代对象。如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描。
这两个次数即上面get_threshold()返回的(700, 10, 10)返回的两个10。也就是说,每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。
同样可以用set_threshold()来调整,比如对2代对象进行更频繁的扫描。
1
2import gc
gc.set_threshold(700, 10, 5)分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
还有两种情况会触发GC机制:
程序退出
调用gc.collect
1 | import gc |
10. 内存管理机制
- python中的内存管理由Python私有堆空间管理。所有Python对象和数据结构都位于私有堆中。程序员无权访问此私有堆。python解释器负责处理这个问题。
Python对象的堆空间分配由Python的内存管理器完成。核心API提供了一些程序员编写代码的工具。
Python还有一个内置的垃圾收集器,它可以回收所有未使用的内存,并使其可用于堆空间。
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就发不能再分配给浮点数。Python 对小整数的定义是 [-5, 257),对于这个范围的数,不会新建对象,直接从小整数对象池中取就可以。
11. 文件打开模式
text = oepn(filePath, 操作方式,编码方式)

12. 单例模式
确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,单例模式是一种对象创建型模式。简单的说就是保证只有一个对象,节约内存空间,我们可以通过修改类中的 __new__方法,实现一个简单的单例类。
什么情况下会用到:假如有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig对象的实例,这就导致系统中存在多个AppConfig的实例对象,在配置文件内容很多的情况下会严重浪费内存资源。类似AppConfig这样的类,我们希望在程序运行期间只存在一个实例对象。
优点:速度快、在使用时不需要创建、直接使用即可。
缺点:可能存在内存浪费
1 | class A: |
13. python函数的嵌套、闭包
函数嵌套:python允许在定义函数的时候,其函数体内又包含另外一个函数的完整定义。像这样定义在其他函数内的函数叫做内部函数,内部函数所在的函数叫做外部函数。
自由变量:未在本地作用域中定义的变量。例如定义在内存函数外的外层函数的作用域中的变量。
闭包:在一个外函数中定义一个内函数,内函数运用了外函数的临时变量,并且外函数的返回值是内函数的引用,这样就构成了一个闭包。
- 闭包函数必须满足两个条件:1.函数内部定义的函数 2.包含对外部作用域而非全局作用域的引用
- 闭包函数的特点:1.自带作用域 2.延迟计算
一般情况下,函数结束,会释放内部变量,但是闭包情况下,如果外部函数结束发现自己有临时变量将来会在内部函数用到,就把这个临时变量绑定给了内部函数,然后自己在结束
一些例子
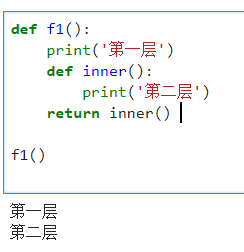
- 外层函数返回的是一个函数名的话,就返回‘第一层’

- 外层函数返回的是函数调用的话,结果为 第一层 第二层
外部函数定义一个数值变量,形成闭包需要加入nonlocal

其他情况下定义某个对象直接可以传入内部函数,只有再次调用函数f才能输出闭包内函数的结果

14. python装饰器、生成器、迭代器
一、装饰器
函数可以作为参数传递,常用作插入日志、性能测试、事务处理、缓存和权限校验等场景。其方式为外部函数传入被装饰函数名,内部函数返回装饰函数名。(大白话说感觉就是有一个函数被另一个函数修饰了一下)
应用场景:
日志
表单验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def pre_validate(func):
def wrapper(*args, **kw):
if not isinstance(args[0], str):
# isinstance(参数1,参数2),如果1和2类型相同,返回True,否则为False
raise BaseException("first argument need string")
else:
return func(*args, **kw)
return wrapper
def validate_string(string):
print(string)
validate_string('required')
validate_string(1)
特点:
- 1.不修改被装饰函数的调用方式
- 2.不修改被装饰函数的源代码
- 3.为待装饰函数增加额外的功能
- 4.返回值为已装饰的函数对象
- 1.不修改被装饰函数的调用方式
1 | import time |
二、生成器与迭代器
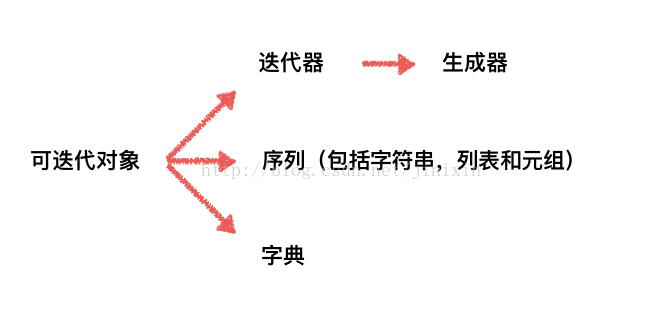
可迭代对象包含迭代器。 如果一个对象拥有__iter__方法,其是可迭代对象;如果一个对象拥有next方法,其是迭代器。 定义可迭代对象,必须实现__iter__方法;定义迭代器,必须实现__iter__和next方法。
- 迭代器
- 可遍历和迭代的对象
- 可以被next()函数调用并不断返回下一个值的对象称为迭代器
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束;迭代器只能往前不会后退。
- 迭代器有两个基本的方法:iter()和next() iter返回的是当前对象的迭代器类的实例
- 可以使用isinstance()判断一个对象是否是迭代器对象(iterator)
- python3中 range(n)生成的是迭代器对象;Python2中xrange(n)生成的才是迭代器对象???
生成器
自动实现了迭代器协议,即iter和next方法,生成器在迭代的过程中可以改变当前迭代值,而修改普通迭代器的当前迭代值往往会发生异常,影响程序的执行。
- 生成器的本质就是迭代器。生成器包括两种:生成器函数和生成器表达式
- 生成器函数:一个包含yield关键字的函数就是一个生成器函数。并且yield不能和return共用,并且yield只能用在函数内。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
- 生成器函数执行之后会得到一个生成器作为返回值,并不会执行函数体。
- 执行了__next__()方法之后才会执行函数体,并且获得返回值。
- next()内置方法,内部调用生成器函数的__next__()方法。
- yield和return相同的是可以返回值,但是不同的是yield 不会结束函数
- 生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表,按需取出对象。注意生成器用()包裹起来,可以节省内存。
- 生成器函数:一个包含yield关键字的函数就是一个生成器函数。并且yield不能和return共用,并且yield只能用在函数内。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次重它离开的地方继续执行
生成器作用:可以实现多任务(协程-->模拟并发)。
生成器类似于一种数据类型,这种数据类型自动实现了迭代器协议,所以生成器也是迭代器。
- 生成器实例
1 | def fib(n): |
15. Python类可以定义哪几种方法:静态方法和类应用场景
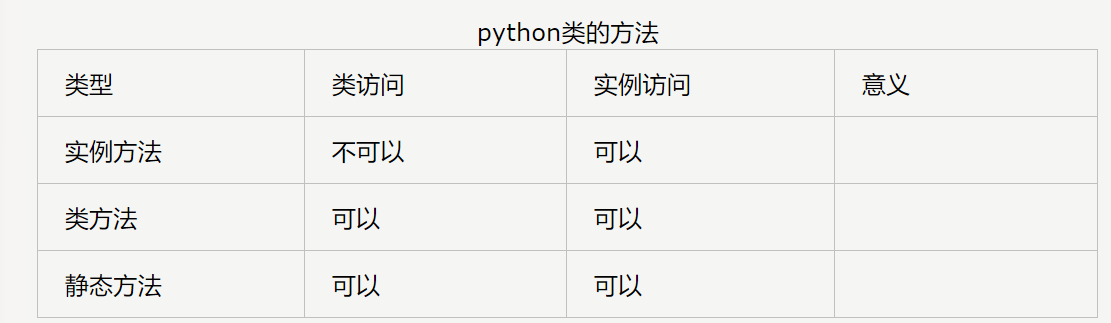
python中实现静态方法和类方法都是依赖于python的装饰器来实现的。 对象方法有self参数,类方法有cls参数,静态方法不需要这些附加参数。
- 静态方法
要在类中使用静态方法,需在类成员函数前面加上@staticmethod标记符,以表示下面的成员函数是静态函数。使用静态方法的好处是,不需要定义实例即可使用这个方法。另外,多个实例共享此静态方法(静态方法无法访问类属性、实例属性,相当于一个相对独立的方法,跟类其实没什么关系,简单讲,静态方法就是放在一个类的作用域里的函数而已)。
一般用于和类对象以及实例对象无关的代码。不需要传递参数,但是还想归为自己的一类,举例子,创建一个三角形类,一个正方向类,判断能否构成这样的类,在两个类对象中分别加入一个静态方法用于各自的判断
- 类方法
类方法与普通的成员函数和静态函数有不同之处。定义: 一个类方法就可以通过类或它的实例来调用的方法, 不管你是用类来调用这个方法还是类实例调用这个方法,该方法的第一个参数总是定义该方法的类对象。 也即是方法的第一个参数都是类对象而不是实例对象. 按照习惯,类方法的第一个形参被命名为 cls。任何时候定义类方法都不是必须的(类方法能实现的功能都可以通过定义一个普通函数来实现,只要这个函数接受一个类对象做为参数就可以了)。同时,类方法可以访问类属性,无法访问实例属性。上述的变量grade,在类里是类变量,在实例中又是实例变量,所以使用的时候要注意,使用好的话功能很强大,使用不好容易混淆。
当一个方法中只涉及到静态属性的时候可以使用类方法(类方法用来修改类属性)
16. __init__函数,init.py的区别
一个包是一个带有特殊文件 __init__.py 的目录。__init__.py 文件定义了包的属性和方法。其实它可以什么也不定义;可以只是一个空文件,但是必须存在。如果 __init__.py 不存在,这个目录就仅仅是一个目录,而不是一个包,它就不能被导入或者包含其它的模块和嵌套包。
发现在引入package的过程中,init.py会运行,因此,如果某些变量或方法需要常驻内存,可以将它们写入init.py文件中。
init.py 中还有一个重要的变量,叫做 all。我们有时会使出一招“全部导入”,也就是这样:
1 | from PackageName import * |
17. 怎样调用父类方法
- 直接写类名调用
- 用 super(type, obj).method(arg)方法调用。
18. Base64
简介:Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符(包括a-z、A-Z、0-9、/、+)来表示二进制数据的方法。Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。
base64 并不是用来加密数据,而是实现在文本协议中传递二进制内容。如 html mime
1 | import base64 |
19. python的反射机制
反射就是通过字符串的形式,导入模块;通过字符串的形式,去模块寻找指定函数,并执行。利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
https://www.cnblogs.com/Guido-admirers/p/6206212.html
20. 什么是PYTHONPATH?
Pythonpath是导入模块时使用的环境变量。每当导入模块时,也会查找PYTHONPATH以检查各个目录中是否存在导入的模块。解释器使用它来确定要加载的模块。
PYTHONPATH是Python中一个重要的环境变量,用于在导入模块的时候搜索路径
1 | import sys |
可以看到,路径列表的第一个元素为空字符串,代表的是相对路径下的当前目录.
由于在导入模块的时候,解释器会按照列表的顺序搜索,直到找到第一个模块,所以优先导入的模块为同一目录下的模块.
导入模块时搜索路径的顺序也可以改变.这里分两种情况:
1,通过sys.path.append(),sys.path.insert()等方法来改变,这种方法当重新启动解释器的时候,原来的设置会失效.
2,改变PYTHONPATH,这种设置方法永久有效:
在这种情况下,可以通过在sys.path列表显示的路径中添加.pth文件来实现
今日分享结束~