秋招以来,为了找工作又学习了很多python相关的知识,给大家分享一下,里面好多内容都是我东拼西凑出来的(如果是借鉴了其他博客的,希望大家可以指出,我会标注上),感觉都是比较常见的或者被问到的。
希望这篇分享会对大家找工作有所帮助~
1. python语言特性
Python是一种解释型语言。与C语言等语言不同,Python不需要在运行之前进行编译。
Python是动态语言,当声明变量或类似变量时,不需要声明变量的类型。编写Python代码很快,但运行比较慢。
- 静态语言是在编译时变量的数据类型即可确定的语言
- 动态语言是在运行时确定数据类型的语言。变量使用之前不需要类型声明,通常变量的类型是被赋值的那个值的类型。
我们平时写的代码,需要编译,计算机才能执行。
解释执行(动态编译):解释一句,执行一句。启动速度更快、内存占用少,但是效率低,非独立
编译执行(静态编译):只需要编译一次,可以多次运行。执行效率高。对于大型项目通常采用编译执行的语言。
2. 基本的数据结构
不可变数据类型:数值型(number:int, float,bool,complex)、字符串型string、元组tuple
可变数据类型:列表和字典
序列结构:
- list:列表是一种序列,可以看做是一种数组,但不同的于其它语言的是,Python列表中的元素可以是任何数据类型,诸如,数字、字符串等等。
- 是基于数组或者链表实现的,所以有序。
- list中的元素就是指针。是长度可变的数组,每次都会分配略大的内存防止频繁的申请分配内存,连续的一块的内存。
- tuple:元组和列表一样,都以看做是一种数组,元素可以是任何数据类型,甚至可以嵌套。同样元组可切片,切片方法同list,但是元组使用小括号创建。
- 相对于 list 而言,tuple 是不可变的,元组内的元素一旦创建,是不可修改的,也不可追加,这使得它可以作为 dict 的 key,或者扔进 set 里,而 list 则不行。但可以用切片的方式更新元组。
- tuple 放弃了对元素的增删(内存结构设计上变的更精简),换取的是性能上的提升:创建 tuple 比 list 要快,存储空间比 list 占用更小。所以就出现了“能用 tuple 的地方就不用 list”的说法。
- 多线程并发的时候,tuple 是不需要加锁的,不用担心安全问题,编写也简单多了
- 如果要创建的元组中只有一个元素,要在它的后面加上一个逗号‘,’,元组里只有一个元素的时候,逗号(,)非常重要。
- list:列表是一种序列,可以看做是一种数组,但不同的于其它语言的是,Python列表中的元素可以是任何数据类型,诸如,数字、字符串等等。
散列结构
散列结构中,元素顺序是不重要的,顺序不同的散列,还是同一个散列。散列结构有set、dict。
set,集合,集合是由不重复元素组成的无序的集,重点是不重复,和数学中的集合类似。无序是散列结构的特点,集合是一种散列结构,所以集合也有无序的特点。set是hash实现的,所以是无序的
- dict,字典,字典由键值对组成,具有唯一性,可变性。字典是通过散列表或说哈希表实现的。
- 字典是可变对象但字典的键的唯一的,是不可变对象,因为要确保经过Hash算法以后得到的地址唯一。
- 字典遍历时,时间复杂度取决于字典拥有的最大键值对的数量,即使key被remove,但是依旧保持这个hash,首先链地址法是可以直接删除元素的,但是开放定址法是不行的,正确做法应该是删除之后置入一个原来不存在的数据,比如-1
- 字典的三个基本操作(添加元素、获取元素、删除元素)的平均时间复杂度为O(1)
- 字典用链地址法解决冲突
- 理解字典的最好方式,就是将它看做是一个 键 : 值对的集合。字典的无序是指数据存进字典的顺序跟取出字典的顺序不一致python3.6之前是无序的,是有序的。
3. Python中的赋值(复制)、浅拷贝与深拷贝
- 复制不可变数据类型,不管如何,都是同一个地址
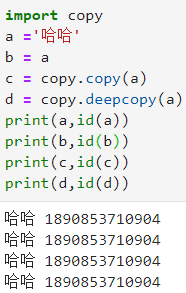
- 复制可变数据类型
- 赋值: 只是复制了新对象的引用,不会开辟新的内存空间。
- 浅拷贝: 创建新对象,其内容是原对象的引用。浅拷贝之所以称为浅拷贝,是它仅仅只拷贝了一层,拷贝了最外围的对象本身
- 当浅复制的值是不可变对象(字符串、元组、数值类型)时和“赋值”的情况一样,对象的id值(id()函数用于获取对象的内存地址)与浅复制原来的值相同。
- 当浅复制的值是可变对象(列表、字典、集合)时会产生一个“不是那么独立的对象”存在。有两种情况:
- 第一种情况:复制的对象中无复杂子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
- 第二种情况:复制的对象中有复杂子对象(例如列表中的一个子元素是一个列表),如果不改变其中复杂子对象,浅复制的值改变并不会影响原来的值。 但是改变原来的值中的复杂子对象的值会影响浅复制的值。
- 深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。深拷贝出来的对象是一个全新的对象,不再与原来的对象有任何关联。
4. fun(*args,**kwargs)中的*args,**kwargs什么意思?
可以将不定数量的参数传递给一个函数。
*args用来发送一个非键值对的可变数量的参数列表给一个函数(元组的方式传参)
**kwargs用来发送一个键值对的可变参数量的参数列表给一个函数(字典的方式传参)

5. python中什么元素为假
0,空字符串,空列表,空字典。空元组,none, False
6. python传参数是传值还是传址
python中函数参数的引用传递(不是传值)。对于不可变类型,传入函数中,不会影响到变量自身。对于不可变类型,会更改变量自身。
7. 单引号和双引号区别

8. 关于python中的复数
- 复数的语法:real+image j
- 实部和虚部都是浮点数
- 虚部的后缀可以是j也可以是J
- 复数的conjugate方法可以返回该复数的共轭复数
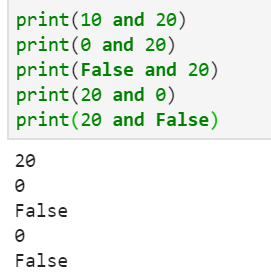
9. python逻辑运算符
and,同真取最后一个真,有假取假
or,只要第一个不是假就取第一个的值,否则一律取第二个数的值
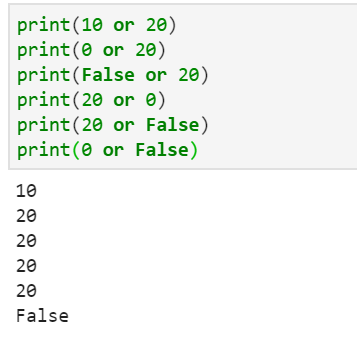
not 取反,返回True或者False
10. python比较运算符
比较运算符优先级大于逻辑运算符
比较两个字符时,是比较ASCII码
python不支持复数比较大小,抛出TypeError错误
python支持连续比较:
3>2>2等价于3>2and2>2,返回结果为Falsepython3不支持数字和字符串比较,报错为TypeError。python2支持,如
(2,3)<('a','b'),从第一个元素的ASCII码开始比较,直到两个元素不相等为止,如果前面都相等,那么元素个数多的tuple较大字符串比较也是从第一个字符的ASCII码开始比较,直到两个字符不相等为止
字母和数字的ASCII码范围:'az'>'AZ'>'0~9'(61-7A)>(41-5A)>(30-39)
11. python中的return
- return可以有多个返回值
- 没有返回值时,函数自动返回None
- 执行到return时,程序将停止函数return后面的语句
12. python中的重载和重写
重载:在一个类里,方法的名字相同参数不同,返回类型可以相同也可以不同;重载是让类以统一的方式处理不同类型数据的一种手段。
函数重载想要解决的问题:可变参数类型、可变参数个数。
另外,一个基本的设计原则是,仅仅当两个函数除了参数类型和参数个数不同以外,其功能是完全相同的,此时才使用函数重载,如果两个函数的功能其实不同,那么不应当使用重载,而应当使用一个名字不同的函数。
在python中, 可以接受任何类型的参数,如果函数的功能相同,那么不同的参数类型在 python 中很可能是相同的代码,没有必要做成两个不同函数。除此之外,python对那些缺少的参数设定为缺省参数。故python 不需要函数重载。
重写:子类不想原封不动地继承父类的方法,而是想做一定的修改,就需要用到方法的重写,又称为方法的覆盖
13. python模块导入
1 | from xxx import yyy |
14. python中的栈和队列
都可以直接用列表来实现
栈:stack = []
- 入栈:stack.append()
- 出栈:stack.pop()
队列:queue = []
入队:queue.append()
出队:queue.pop(0)
1
2
3
4from collections import deque
q = deque()
q.append('eat')
q.popleft()
15. python is 和 == 区别
==用来比较判断两个对象的value(值)是否相等
is比较判断的是对象间的唯一身份标识,也就是id是否相同
总的来说,只有数值型和字符串型,并且在通用对象池中的情况下,a is b才为True,否则当a和b是int,str,tuple,list,dict或set型时,a is b均为False。
1 | a = [] |
输出为False
16. 列出5个Python标准库
这里我就随便找了几个,大家可以自己多了解一下
- os: 提供与操作系统相关联的函数,这个库就是对操作系统的封装。os.path 是文件路径相关的操作,对于 Linux,Windows 不同的操作系统下不同的文件路径表示方法提供统一的接口。其他的还有文件夹的创建删除,文件权限的修改,执行命令等等,在不同的操作系统下是不同的操作,但是 os 库提供来统一的接口,这样就容易编写操作系统无关的程序了,易于移植。
- sys:通常用于命令行参数。sys模块主要是针对与Python解释器相关的变量和方法,不是主机操作系统。获取python解释器的版本信息:
sys.version,获取操作系统平台:sys.platform获取命令行参数,获取模块的查找路径sys.path - re: 正则匹配
- math: 数学运算 math.sqrt
- datetime:处理日期时间
a = datetime.date.today()
17. python怎么删除数组中的元素
del:根据索引值删除元素
del 是 Python 中的关键字,专门用来执行删除操作,它不仅可以删除整个列表,还可以删除列表中的某些元素。
del 可以删除列表中的单个元素,格式为:
del listname[index]del 也可以删除中间一段连续的元素,格式为:
del listname[start : end]其中,start 表示起始索引,end 表示结束索引。del 会删除从索引 start 到 end 之间的元素,不包括 end 位置的元素。
pop():根据索引值删除元素
pop() 方法用来删除列表中指定索引处的元素,具体格式如下:
listname.pop(index)大部分编程语言都会提供和 pop() 相对应的方法,就是 push(),该方法用来将元素添加到列表的尾部,类似于数据结构中的“入栈”操作。但是 Python 是个例外,Python 并没有提供 push() 方法,因为完全可以使用 append() 来代替 push() 的功能。
remove():根据元素值进行删除
- 该方法会根据元素本身的值来进行删除操作。
- 需要注意的是,remove() 方法只会删除第一个和指定值相同的元素,而且必须保证该元素是存在的,否则会引发 ValueError 错误。
- remove() 方法使用示例:
1 | nums = [40, 36, 89, 2, 36, 100, 7]#第一次删除36 |
运行结果:
[40, 89, 2, 36, 100, 7] [40, 89, 2, 100, 7] Traceback (most recent call last): File "C:.py", line 9, in
最后一次删除,因为 78 不存在导致报错,所以我们在使用 remove() 删除元素时最好提前判断一下。
- clear():删除列表所有元素
1 | url = list("http://c.biancheng.net/python/") |
18. python字典操作
items()、keys()、values() 分别用于获取字典中的所有 key-value 对、所有 key、所有 value。这三个方法依次返回 dict_items、dict_keys 和 dict_values 对象,Python 不希望用户直接操作这几个方法,但可通过 list() 函数把它们转换成列表。
(1)字典如何删除键和合并两个字典
1 | dic = {'name':'zym','age':18} |
(2)字典根据键从小到大排序
sorted(dict.items(),key=lambda i:i[0],reverse = False)
19. Python的位运算
| 符号 | 描述 | 运算规则 by MoreWindows |
|---|---|---|
| & | 与 | 两个位都为1时,结果才为1 (统计奇数) |
| | | 或 | 两个位都为0时,结果才为0 (统计偶数) |
| ^ | 异或 | 两个位相同为0,相异为1 (常用统计不相同数) |
| ~ | 取反 | 0变1,1变0 |
| << | 左移 | 各二进位全部左移若干位,高位丢弃,低位补0 |
| >> | 右移 | 各二进位全部右移若干位,对无符号数,高位补0,有符号数,各编译器处理方法不一样,有的补符号位(算术右移),有的补0(逻辑右移) |
好啦,今日分享到此,后续会继续更新有关知识点的总结~:)